Extracting meaningful insights from vast text datasets is a common challenge. In my work, I often collaborate with non-technical subject matter experts who have important questions and rich data, but get lost when a dataset outgrows excel (~1 million rows).
I recently co-authored on such a project. In this post, I share how we successfully merged quantitative (ie. data science) and qualitative (ie. domain) expertise to analyze a terabyte of news articles from British and German newspapers. We asked: how did the media express solidarity with migrant women during the Covid-19 pandemic.
The lead researcher was especially interested in understanding “solidarity”, but ran into the familiar problem of trying to describe a “fuzzy” or complex and hard-to-define concept that doesn’t lend itself to simple keywords. We opted for a mixed-methods exploratory approach that relies on machine learning based “intelligent sampling”.
Why Mixed-Methods Text Analysis?
- Quantitative Limits: Automated techniques like topic modeling or sentiment analysis can scale efficiently, but often miss subtleties like sarcasm, implicit bias, or subtle framing. Automation risks sacrificing the “how” and “why” of communication.
- Qualitative Constraints: Discourse analysis excels at optimizing subject matter expertise. Through deep reading and careful evaluation, the researcher uncovers detailed and contextualized insights. This level of care is impossible for massive datasets, thus limiting generalizability.
The Approach
Our mixed-methods approach involved three key phases (Figure 1):
Figure 1: Overview of Methods and Sampling Approach.

- Macro Level Quantitative Analysis: The goal of this phase was to map the terrain in order to identify a promising sample of relevant articles. First, we used comparable migrant-related keywords in German and English to retrieve ~19,000 news articles mentioning migrants from the news database. Then we used an unsupervised machine learning method (LDA topic modelling) to group articles into 60 different topics, followed by hierarchical cluster analysis to merge topics into 6 general themes (Table 1).
Table 1: Descriptions of Topics and Cluster Analysis Results.
Figure 2: Topic Clusters and Proportion of Articles Mentioning Female Migrants.
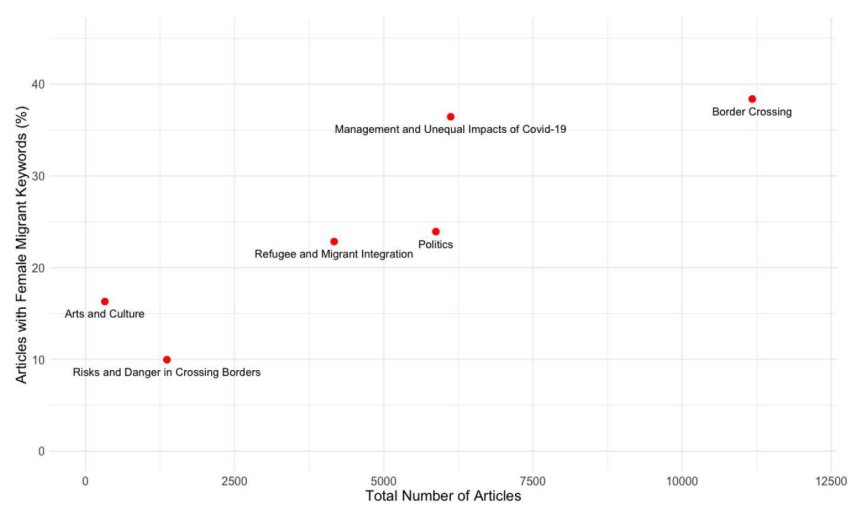
- Micro Level Qualitative Analysis: Next, we identified the relevant cluster “Management and Unequal Impacts of Covid 19” from which we randomly sampled 187 relevant articles for the qualitative deep dive (Figure 2). This phase uncovered the contexts, the subtle framing, and the ‘how’ and ‘why’ behind the quantitative patterns.
For example, qualitative results showed how migrant women in particular were more often framed as victims or vulnerable in the news than men. Another finding was a focus on narratives comparing which migrant groups were most deserving of support, rather than unconditional solidarity. These contextualized findings would have been missed by fully automated techniques like sentiment analysis or classification algorithms.
- Multi Level Validation: Finally, we used qualitative findings to inform further computational analysis. Techniques such as word embeddings operate by identifying semantic patterns in data. Although quantitative, these patterns require an uncomfortable level of subjective evaluation and benefit from subject expertise. We found that qualitative findings generalized to semantic similarity in the larger sample. For example, the word “Vulnerable” was more closely related to migrant women than to men (Figure 3).
Figure 3: Results from Word Embedding Semantic Similarity, Adjectives Most Associated with Comparison Groups.

Relevance to Applied Data Science
- Analyzing Large-Scale Unstructured Data: For projects involving massive text datasets, this “intelligent sampling” approach allows teams to strategically target deep-dive analysis. This makes the exploration of terabytes of data feasible and cost-effective by narrowing the scope for detailed manual effort.
- Translating Complex Business Questions into Measurable Insights: When analyzing ‘fuzzy’ but critical concepts (e.g., evolving public discourse, brand loyalty, subtle expressions of sentiment), this framework enables data teams to operationalize subject matter expertise. It can provide insights that go deeper than surface-level keyword analysis or oversimplified machine learning approaches.
- Enhancing the Value of Subject Matter Expertise: This approach provides a clear methodology for integrating deep domain knowledge with large-scale computational analysis. It facilitates effective collaboration between data scientists and non-technical subject matter experts, ensuring that automation is guided by domain knowledge and that important qualitative findings can generalize across larger samples.
Communication between “technical people” and “domain experts” is often one of the biggest challenges in interdisciplinary projects. The strength of this mixed-methods text analysis lies in its sequential integration of quantitative and qualitative expertise, allowing each to shine where it is most useful. Computational techniques identify broad trends and relevant samples, while discourse analysis discovers nuanced, contextualized insights. At best, data science is a team sport where people with diverse skill sets work together to achieve a more complete understanding of the data than any single perspective could provide.
Not Done Reading?
The full paper is available at https://doi.org/10.1080/01419870.2024.2362456.