Does your big data text analysis include multiple languages? Whether you’re analyzing trending news across borders or evaluating the impact of an international marketing campaign, you may be underestimating the difficulty of finding comparable texts across different languages. Although the first instinct may be to use Google Translate or DeepL to automate translation (e.g. assuming a German search for “Einwanderung” aligns with an English search for “immigration”), research shows that automated translations often introduce subtle semantic shifts or changes in meaning. This project demonstrates how to retrieve multilingual and culturally aligned document samples, leading to more accurate cross-lingual comparisons. This approach is especially relevant within the European context, in which there are 24 official EU languages and an estimated 284 spoken languages.
Figure 1: Interactive Map Showing Europe (Grey), EU Member States (Blue) and Included Languages (Yellow).
The Challenge: Consistent Document Retrieval Across Diverse Languages
In this research, we compared strategies for retrieving relevant documents about immigration from European Parliament debates, across six languages: English, German, Spanish, Polish, Hungarian, and Swedish (Figure 1). We included traditional keyword search approaches and semantic similarity methods, using a multilingual corpus of parliamentary proceedings dating back to 2012 (when the UK was still an EU member).
To evaluate multilingual retrieval methods, we included English-only search as a baseline. Our language sample represents a mix of high-resource and low-resource languages, reflecting how differences in training data availability can affect machine translation accuracy.
We compared three multilingual search approaches:
- Expert-Validated Translated Queries: English keywords machine translated to each language and subsequently validated by native speakers.
- Machine Translated Queries: English keywords automatically translated without human validation (using DeepL).
- Multilingual Semantic Similarity Search: Using an English query to find semantically similar documents from other languages via bilingual aligned word embeddings in a vector database (Elasticsearch).
Key Findings: Validation is the Gold Standard, but Semantic Search Can Help
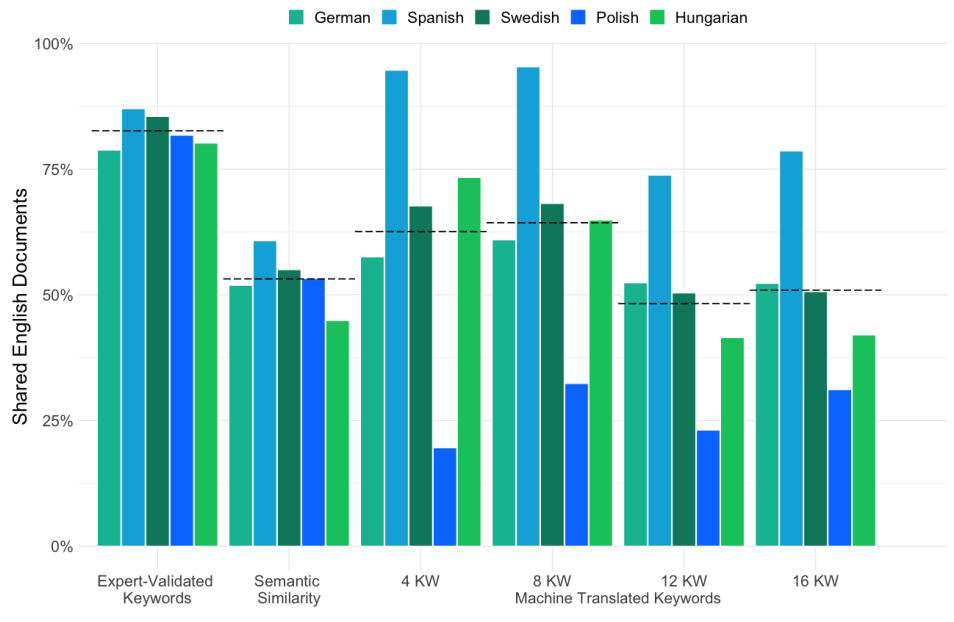
Expert Validation Wins for Keywords: Queries translated and validated by native speakers were the most accurate and consistent across languages (Figure 2). They had the highest overall search retrieval accuracy based on F1 scores, and had the highest proportion of documents shared with the English language monolingual search condition (Figure 3). This approach best balances finding relevant documents without including too many irrelevant ones.
Machine Translation Alone is Risky: Simply machine-translating keywords led to varied accuracy. Performance suffered, especially for low-resource languages. For keywords automatically discovered using word-embedding based query expansion my open source rKeywords package, more keywords did not always lead to better results (Figure 3).
Semantic Search is High Recall: Semantic similarity search showed overall lower accuracy, but relatively good consistency across languages. This approach is useful because bilingual word embeddings allow English language queries to discover matching non-English language documents. While generally less precise than validated keywords to retrieve specific documents, this approach can be valuable for exploring new and potentially relevant keywords and documents (i.e. high recall).
Figure 2: Comparison of F1 Scores for Most Effective Queries Across All Approaches and Languages.
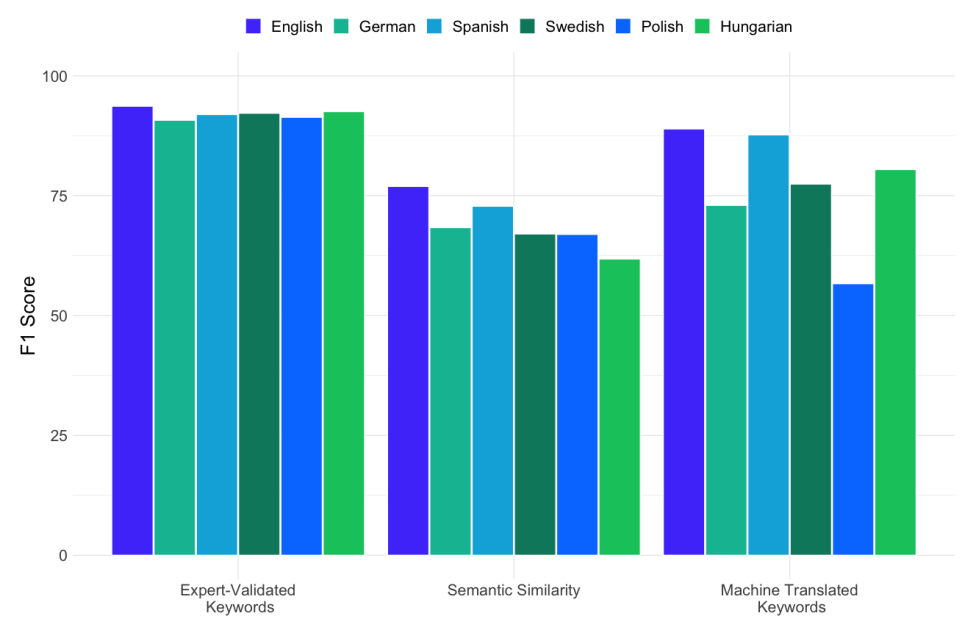
Figure 3: Percent Documents Shared by English and Non-English Queries for All Approaches, using a Dashed Line to Reference Group Average.
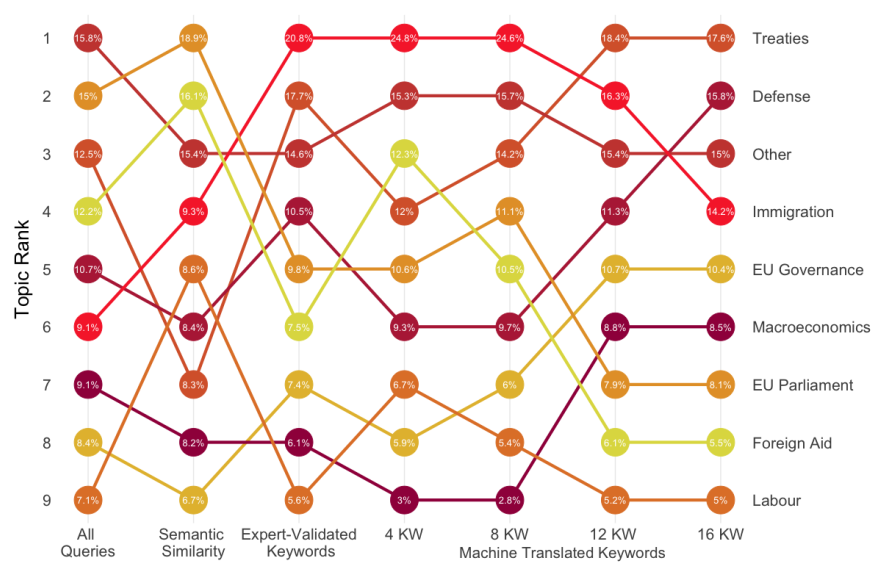
Impact on Your Analysis: Garbage In, Garbage Out The documents you retrieve directly shape your downstream text analysis results. Different search methods yielded different document sets, leading to different topic distributions and, in-turn, significantly different analytical conclusions. For example, comparing topic modelling results from different search condition, we see that the expert validated search condition put “Immigration” as the most occurring topic whereas the broad 16 Keywords machine-translation search condition places “Treaties” at the top with “Immigration” in fourth place (Figure 4).
Figure 4: Change in Topic Rank Across All Search Conditions.
Tips for Multilingual Research:
- Validate Translated Keywords: Don’t just rely on raw machine translation to translate search queries. DeepL and Google Translate are easy but imperfect. Native speaker validation is crucial at the information retrieval stage.
- Consider Semantic Search Strategically: While increasingly popular in NLP, especially for LLM applications, semantic similarity search accuracy is reliant upon optimizing a similarity threshold. This approach is convenient but imprecise. That said, it is still very useful as an unsupervised method for document discovery.
- Be Aware of Language Differences: “The Babel Problem” is real. We have automated tools which can help resolve language differences, but they don’t eliminate all linguistic complexities. Especially for low-resource languages, you should be prepared for a level of error when working on multilingual text analysis.
Relevance for Applied Data Science: These findings are highly relevant for businesses operating in multilingual environments:
- Global Customer Feedback Analysis: When analyzing customer reviews, support tickets, or social media mentions from different countries, ensuring that a search for “product defect” in English finds truly equivalent complaints across all languages is vital. Expert-validated translations of search terms are key.
- International Market Research: Identifying market trends, competitor activities, or regulatory changes across regions requires consistent information retrieval. Relying solely on machine-translated keywords can lead to missing signals and misinterpreting local sentiment or requirements.
- Multilingual Knowledge Base Management: For internal knowledge bases or customer-facing FAQs, ensuring that searches in one language can effectively surface relevant documents requires robust cross-lingual retrieval. Hybrid semantic search can be useful for this challenge, when supplemented by validated keywords.
Careful document retrieval is foundational in text analysis. In multilingual contexts, it directly impacts quality of samples and accurate results. Whereas semantic search via vector databases provides a pathway towards full automation of multilingual document retrieval, human validation of machine translations remains the scalable and reliable gold standard.
Interested in the Full Implementation?