Large Language Models (LLMs) have transformed how we access information, offering a predictive, search-like interface powered by their training on vast web-scale datasets. However, most critical data remains safeguarded within traditional databases, accessible only through keyword searches or complex SQL queries. For document retrieval, keyword-based queries (terms meant to match specific concepts in the target text) are still the norm.
For example, to retrieve documents about female politicians from a news database a Boolean query may look like:
(woman OR mother OR she OR her) AND (politician OR representative OR senator OR mayor).
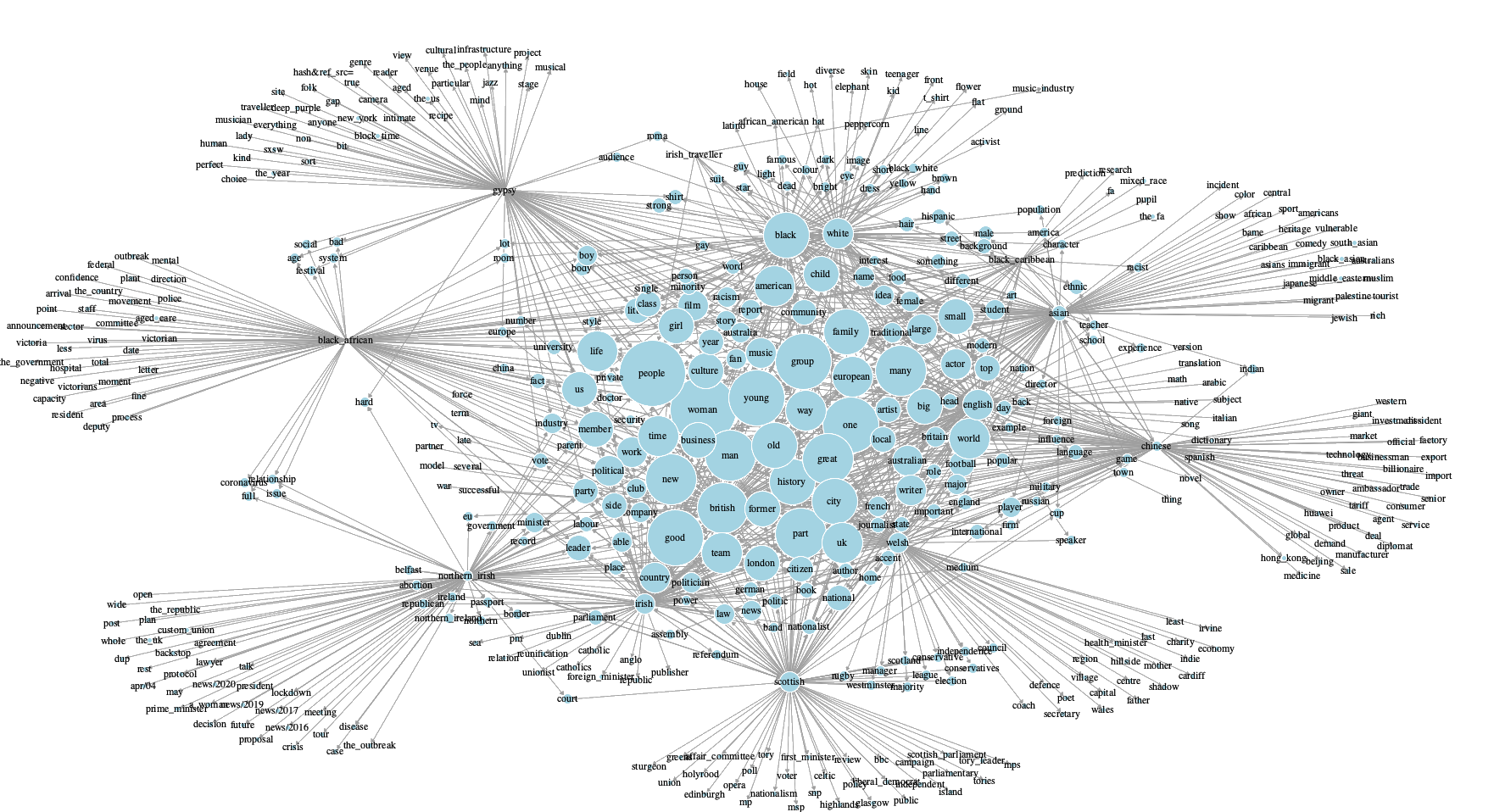
Manually generating these keywords is labor-intensive, prone to knowledge gaps, personal biases and irrelevant results. This project explores how we might simplify this process using LLMs. I investigate using pre-trained LLMs, combined with a prompting technique called Tree-of-Thoughts (ToT), to automatically generate sophisticated Boolean search queries. I apply this method to the domain of “Identity”, a complex and sensitive area that illustrates the flexibility of this approach (Figure 1).
Figure 1: Network Analysis of “Identity” Related Keywords.
Introducing Tree-of-Thoughts (ToT) Prompting
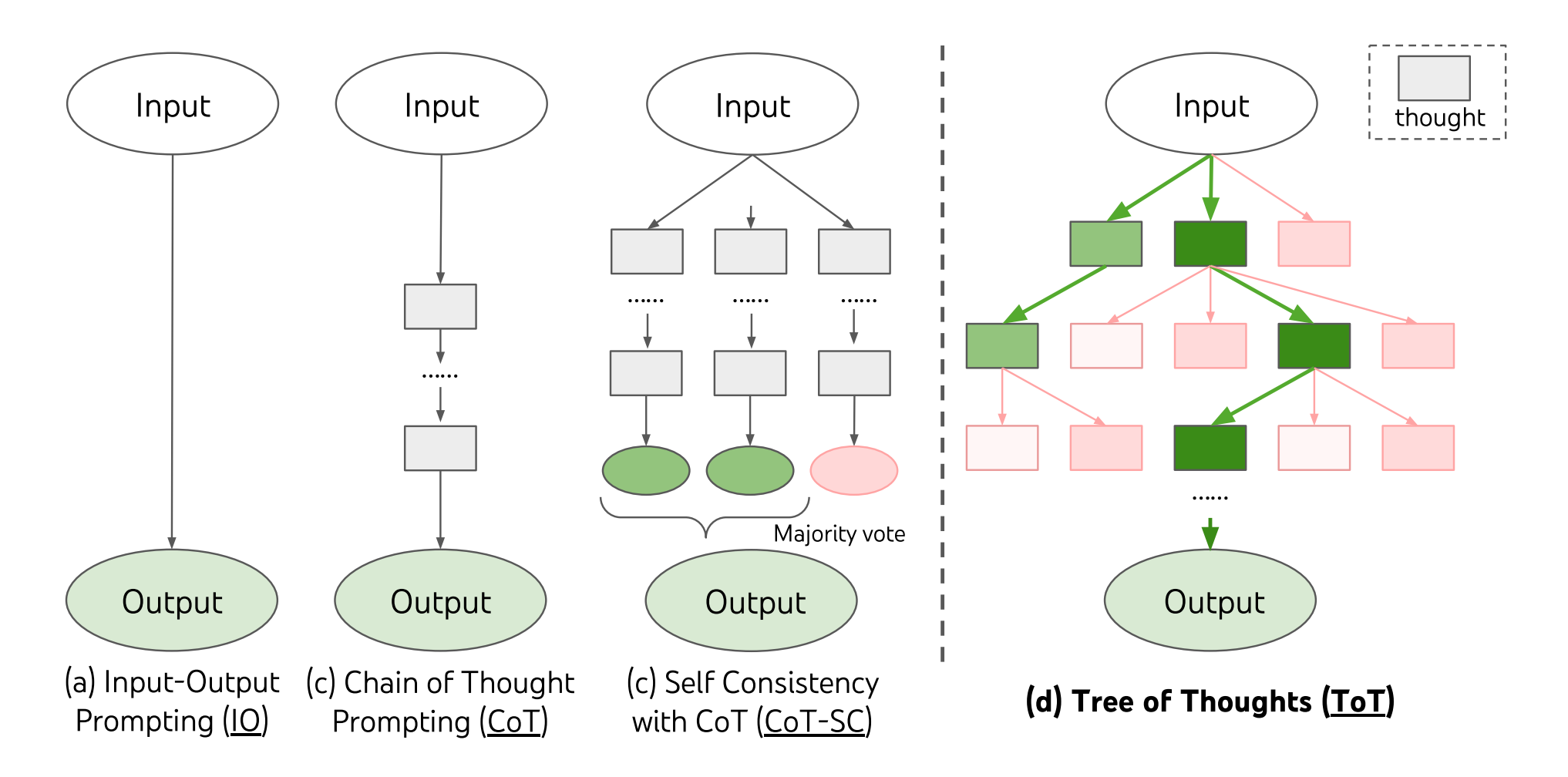
LLMs offer a powerful and accessible solution, but a basic prompt like “Give me all keywords for X” fails to generate optimal queries. A more complex prompting method known as Tree-of-Thoughts (ToT) prompting guides an LLM to explore multiple reasoning paths, evaluate intermediate steps (“thoughts”), and decide which path to pursue. As seen in Figure 2, instead of a single line of thought like simple Input-Output prompting or Chain-of-Thoughts, Tree-of-Thoughts enables the LLM to:
- Decompose: Break down the large task (e.g., “create a search query for gender”) into smaller steps.
- Generate: Create multiple potential solutions or “thoughts” at each step (e.g., several initial keyword sets).
- Evaluate: Assess the quality and relevance of each generated thought, either via LLM self-evaluation or human guidance.
- Search: Like random forest, it intelligently navigates the “tree” of thoughts exploring promising paths and removing less effective ones.
Figure 2: Overview of Increasingly Complex LLM Prompting Approaches.
ToT Generated Search Queries
This method combines LLMs (like GPT-4 or LLama-3) and human-in-the-loop evaluation. Here is a step-by-step process.
The Initial Query (Prompt & Seed Words):
- Define Goal: Clearly state what you want (e.g., “Retrieve documents about gender”).
- Provide Seeds: Give the LLM starting keywords (e.g., “male,” “female”, “man”, “woman”, “intersex”) and (optional) several highly relevant example documents.
- Set Quality Guidelines: Provide your preferences in the prompt, for example “Include terms relevant to {Identity}, including specific labels and communities. Be inclusive. Combine terms using Boolean operators (AND, OR). Group core concept terms (e.g., different gender identities) with OR, then AND this group with terms specifying ‘people’ or ‘community’.”
Iterative Generation & Evaluation (Generate, Expand & Rank):
- Generate Candidates: The LLM produces several initial search query candidates.
- Evaluate & Filter: The LLM evaluates these queries, (optionally) evaluates them using test documents, and removes underperforming queries.
- Expand Promising Queries: Prompt the LLM to add more relevant keywords to the surviving, most promising queries.
- Repeat Cycles: This generate-evaluate-expand cycle is repeated several times (e.g., 5 rounds) to progressively refine the queries.
Human Validation (Refine):
- Review Top Queries: After several iterative cycles, manually review the best-performing search queries.
- Validate & Edit: Remove irrelevant terms or LLM hallucinations. Add any missed keywords based on your domain expertise. This human validation is critical for catching errors, refining LLM output, and ensuring queries align with research goals.
Results:
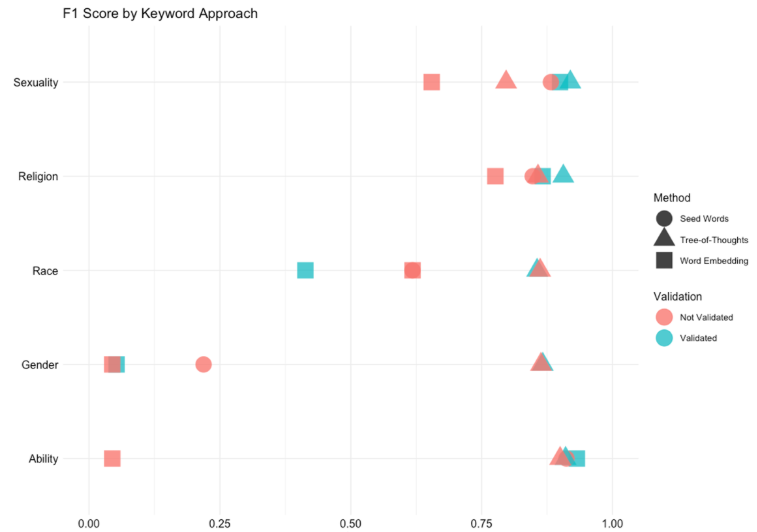
The effectiveness of queries generated through this process was evaluated using a labeled dataset of news articles from The Guardian. This sample included articles related to sexuality (n=624), disability (n=1,142), religion (n=3,271), gender (n=2,074), and race/ethnicity (n=4,169). ToT prompting with human-in-the-loop evaluation produced more accurate queries than other keyword expansion approaches across all identities (Figure 3).
Here is the most accurate generated query for “gender”:
(biological sex OR gender OR sex OR identity OR orientation OR LGBTQ OR LGBTQ OR LGBTQIA+ OR queer) AND (man OR woman OR transexual OR nonbinary OR genderqueer OR cisgender OR male OR female OR transgender OR genderfluid OR agender OR men OR women)
Figure 3: Accuracy Comparison of Keyword Generation and Expansion Approaches.
Relevance for Applied Data Science:
This methodology offers a replicable and scalable framework for:
- Enhanced Information Retrieval: Building robust search capabilities for large, unstructured text corpora across various domains (e.g., legal tech, market research, scientific literature review).
- Feature Engineering: Generating keyword-based features for downstream NLP tasks where simple bag-of-words approaches are insufficient.
- Data Annotation & Collection: Streamlining the creation of targeted datasets by improving the precision and recall of initial data gathering.
- Prompt Engineering Best Practices: Demonstrating an advanced prompting strategy that moves beyond single-shot interactions to achieve complex, multi-step reasoning with LLMs.
By combining the generative power of LLMs with structured prompting, iterative refinement, and human expertise, researchers and data scientists can significantly improve the quality and efficiency of information retrieval for challenging, nuanced domains. This approach represents a practical step towards harnessing LLMs as co-pilots in data collection.
Want to See More? This paper is not yet public, reach out to me directly if you’d like to chat. Code and data will be made available upon project completion. For now, you can download this recent poster which is part of a larger project. Download Poster