Large Language Models (LLMs) are transforming text-as-data research. But as we adopt them across diverse domains, critical questions remain: what are the environmental costs of these models, and is the biggest model always the best choice for every task? This project looks beyond AI hype to evaluate the tradeoff between accuracy and sustainability in large-scale text analysis.
![]()
The Hidden Energy Costs of LLMs
Training massive LLMs consumes vast energy, but the costs don’t stop there. Every time an LLM analyzes your data (inference), it uses more power. This ongoing “inference cost” is a significant, often overlooked, part of an LLM’s ecological footprint.
To put this in perspective, AI companies such as Microsoft (funder of OpenAI), Google and Meta have recently been in the news for purchasing nuclear power plants in order to power their growing AI and data center needs (Crownhart, 2024 and The Guardian, 2025). The Three Mile Island nuclear power plant, renewed by Microsoft, is estimated to produce enough energy to power 800,000 US homes per year.
In this project, we ask if this high energy demand of LLMs is always justified by performance gains?
To find out, we systematically compared several open-source and local LLMs (e.g. Mistral-Nemo 12B, Gemma 3 27B, Deepseek-R1 32B) against traditional, lighter-weight statistical methods (e.g. SVMs, specialized BERTs, spaCy) on common text analysis tasks: sentiment analysis, text classification, and named entity recognition (NER) (Figure 1). We measured accuracy (F1) and agreement with human raters against energy consumption (kWh) and CO2 emissions using CodeCarbon.
Figure 1: Overview of the Research Method, including Analysis Conditions and Measurement Approaches.

Key Findings: Performance vs. Power
LLMs can excel, but often at a steep energy price. For sentiment analysis, LLMs showed high agreement with human raters, but even efficient LLMs used vastly more energy than older statistical methods. For example, the “reasoning” LLM (Deepseek-R1) used almost 100,000 times more energy than simple dictionary approaches.
Specialized, lighter models frequently match or outperform LLMs with far less environmental impact, especially for classification and NER. Fine-tuned BERTs, SVMs, or NLP libraries like Stanza often provided superior or comparable accuracy for a fraction of the energy.
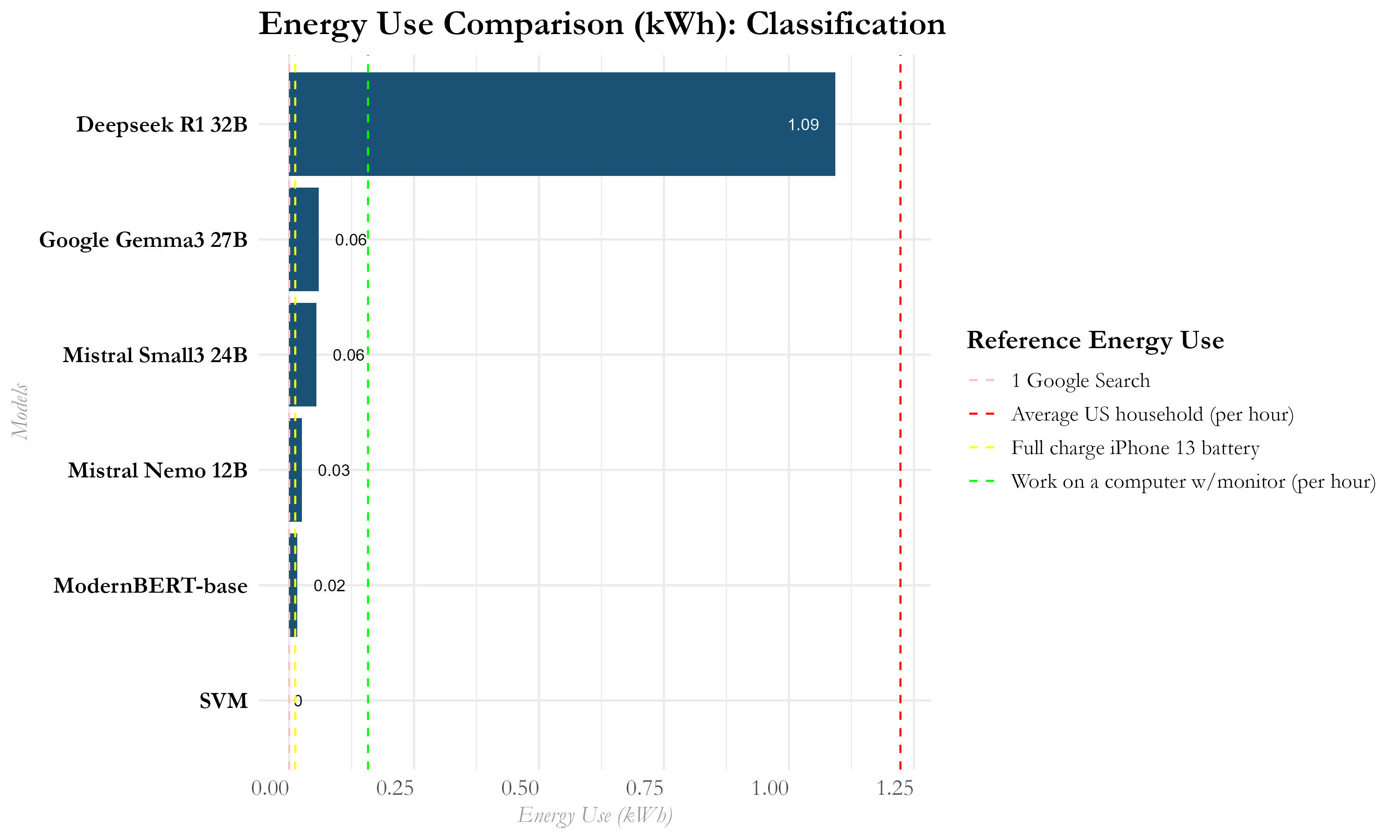
Bigger LLM ≠ Better Performance. Contrary to general Ai performance benchmarks, a larger parameter count didn’t guarantee better results in these specific text analysis tasks (Figure 2). Smaller, efficient models like Mistral-Nemo (12B) often matched or outperformed larger ones like Deepseek-R1 (32B) (Figure 3).
Figure 2: Sentiment Analysis Accuracy Comparison.
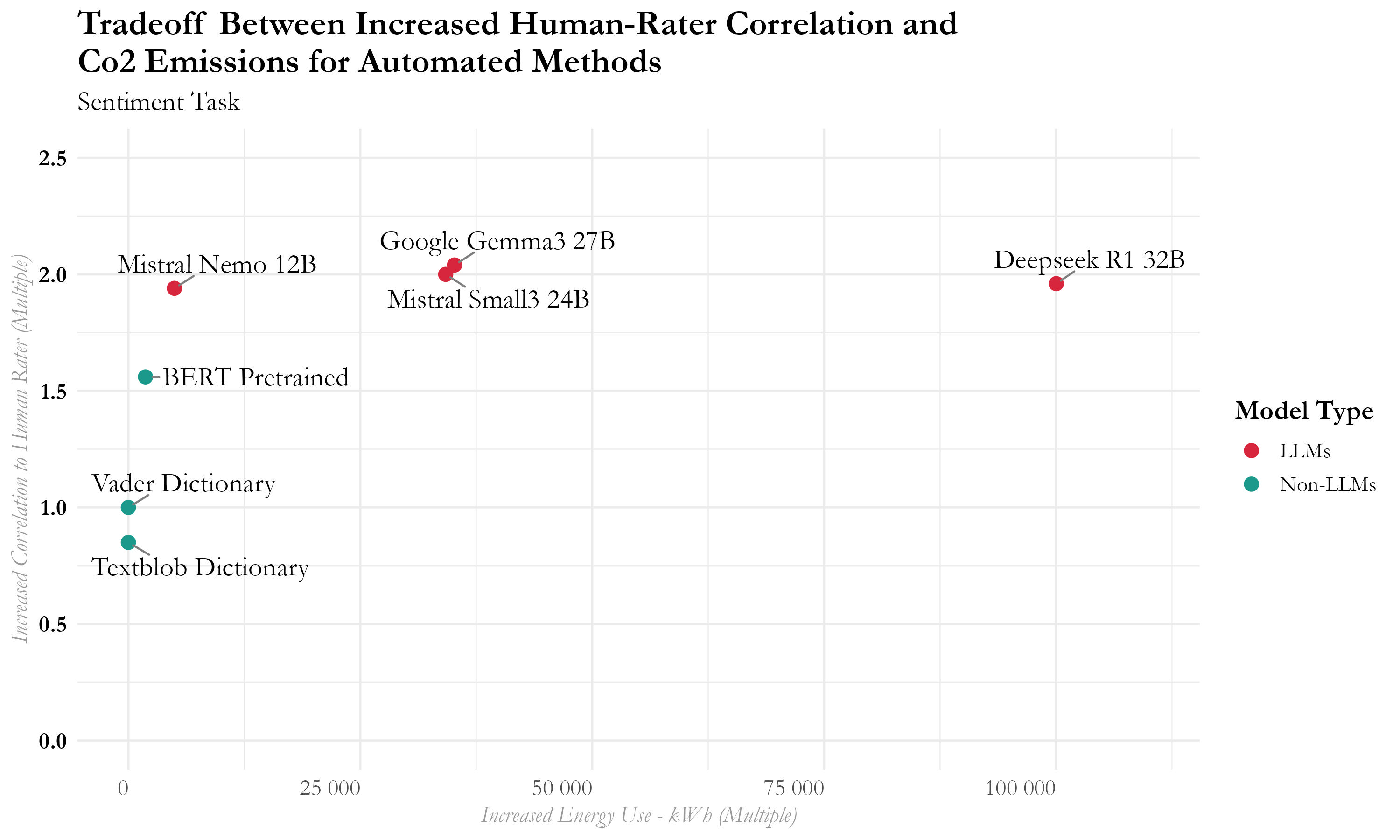
Figure 3: Classification Analysis Energy Comparison.
Introducing the CO2-Adjusted F1 Score
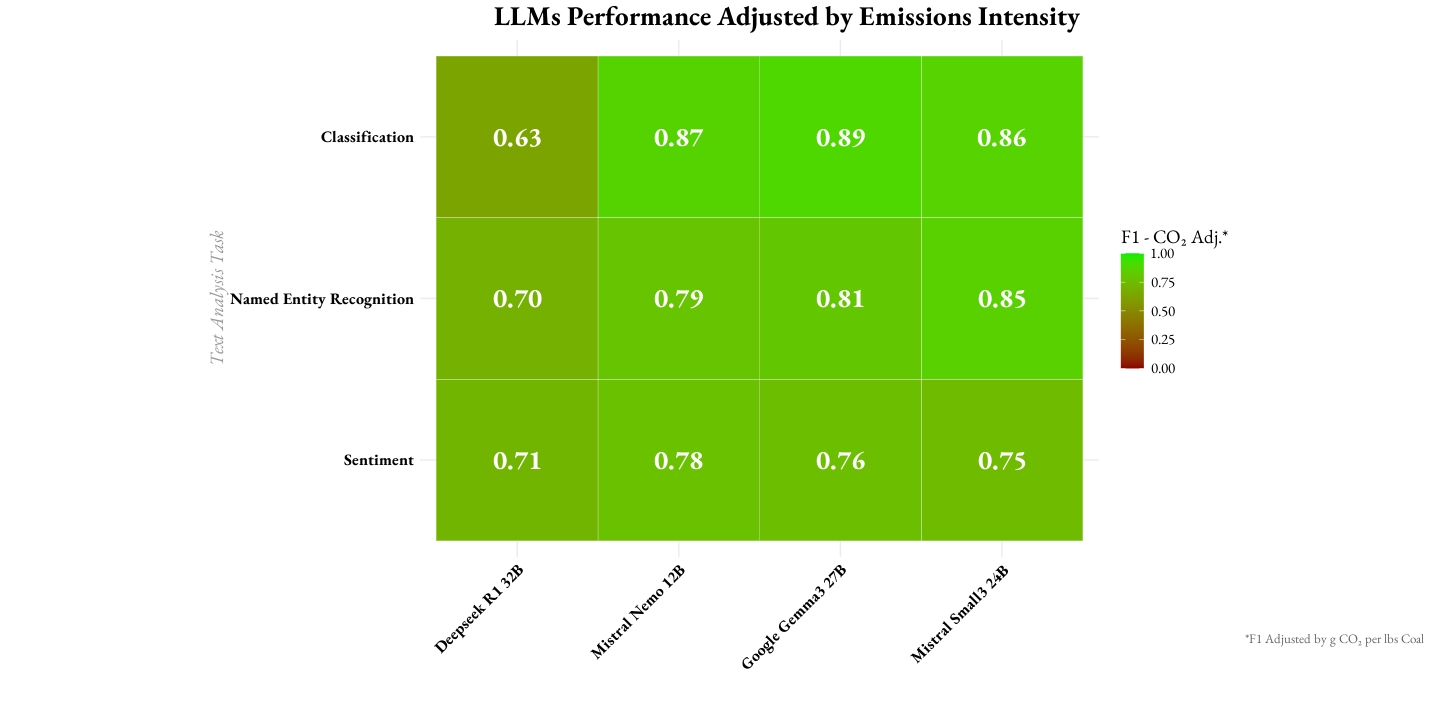
To help make more informed, sustainable choices, we introduce a CO2 Emissions Adjusted F1 score. This metric combines the standard F1 score (measuring precision and recall) with a penalty based on a model’s CO2 emissions for a task. Lower emissions mean a smaller penalty, providing a clearer view of responsible model “efficiency.”
This adjusted score highlighted that while some LLMs offer good raw performance, their environmental cost can significantly diminish their overall value for certain tasks. For instance, Mistral Nemo (the smallest LLM tested) offered the best CO2-adjusted F1 for sentiment analysis (Figure 4).
Figure 4: LLMs Performance and Emissions by Analysis Task.
The “Right-Fit” Philosophy: Think Before You Compute
Don’t default to the largest LLM. General benchmark performance of massive LLMs does not mean better performance on your task.
Consider task-specific, lighter alternatives. They may need training data, but they can be surprisingly effective, cheaper to serve and more sustainable.
Evaluate beyond just accuracy. Factor in energy use, processing time, explainability and overall environmental impact.
Relevance for Applied Data Science: These findings directly impact how businesses should approach AI adoption and deployment:
- Cost Optimization (Compute & Energy): Choosing smaller, “right-fit” models directly translates to lower cloud computing bills and reduced energy consumption, aligning with sustainability goals and improving ROI. The largest and most expensive API endpoint is rarely necessary.
- Scalability & Efficiency: For high-volume tasks like real-time customer support classification or content moderation, lighter models are often faster, more scalable, and have lower latency than massive LLMs, leading to better user experience and operational efficiency.
- Edge Computing & On-Premise Deployment: Smaller, quantized models are more feasible for deployment on edge devices or on-premise servers where computational resources are limited, offering advantages in security, data privacy and IP ownership.
For large-scale text analysis, this means adopting more thoughtful, efficient, and environmentally responsible model selection practices. Critically testing and evaluating text analysis approaches can improve results, reduce costs and align with broader sustainability goals.
Want to See More? This paper is not yet public, reach out to me directly if you’d like to chat. Code and data will be made available upon project completion. For now, you can download this recent presentation. Download Slides